
Ghost 博客付费墙 SEO 完全指南:从机制解析到优化方案
1. 背景
最近写了一篇雅思资源分享的文章,因为不希望被恶意利用以及搜索降权,于是开启了 Ghost 原生的权限管理。从公开改成了会员专属(members only),并在正文加入了部分预览功能( Public Preview)。
然后提交 Google Search Console 还有 Bing Webmaster。本来一气呵成的事情,但是经过一周的等待,发现文章始终没有被两大搜索引擎收录。
我首先怀疑是 Cloudflare 的反爬规则等设置过于严苛,导致谷歌和必应的爬虫被 Cloudflare 阻挡,无法访问网站,自然也就不会收录。折腾了半天也没解决问题,途中还发现开启了 Cloudflare 的 Bot Fight Mode 会导致 Bing 的"测试真实网址"功能(Live Test)失效。
后来才反应过来,问题不在 Cloudflare,而在文章本身的 SEO 设置上。于是开始检查 robots.txt、sitemap、Meta 标签等,最终发现根源在于文章开启了付费墙(Members Only),谷歌的爬虫被阻挡在付费墙之后。虽然有添加公开预览,但预览内容过少,最终被谷歌的算法判定为低质量内容,彻底标记为垃圾页面。
但是经常看华尔街日报(WSJ)、彭博社(Bloomberg)及纽约时报(NYT)的新闻,会发现他们的网站明明也有付费墙,但是谷歌的爬取频率、关键词排名、收录速度等 SEO 指标都非常靠前。不禁让我好奇他们是如何为付费墙内容做 SEO 优化的?他们是如何平衡内容保护与搜索引擎友好这两个核心问题的?
2. Ghost CMS 核心机制与 SEO 原理
Ghost 并非传统的 PHP 博客系统(如 WordPress),它是基于 Node.js 构建的现代应用,采用了 Express 框架处理 HTTP 请求,并使用 Handlebars 作为服务端模板引擎。
2.1 服务端渲染(SSR)与权限控制流程
Ghost 的内容交付管道(Content Delivery Pipeline)是其付费墙机制的核心。与基于 JavaScript 的单页应用(SPA)或“软”付费墙不同,Ghost 的会员系统贯穿于核心路由与渲染逻辑中。
当一个 HTTP 请求到达 Ghost 服务器时,系统会执行严格的中间件检查:
- 请求拦截与身份验证:Ghost 的核心控制器会解析请求头中的 Cookie 或 JSON Web Token (JWT)。系统首先判断当前用户是否持有有效的 ghost-members-ssr 会话标识。
- 上下文注入(Context Injection):如果用户已登录,用户的会员属性(如 status: 'paid', tier: 'premium')会被注入到 Handlebars 的渲染上下文中。如果未登录,上下文中的 @member 对象为空。
- 模板逻辑执行:Handlebars 模板引擎根据上下文数据执行渲染。这是 Ghost 付费墙“硬”特性的根源。在标准的 post.hbs 模板中,通常包含如下逻辑:
- 如果有访问权限:渲染正文,即文章的完整 HTML。
- 如果无访问权限:渲染摘要或经过截断的公开预览(public preview),并附带一个升级提示(Call to Action, CTA)。
这种服务端截断意味着,对于未授权的访问者(包括 Googlebot),文章的付费部分从未被发送到客户端。服务器响应的 HTML 文档在物理上就不包含受保护的内容。
表 2.1:Ghost 原生权限控制与数据流向分析
2.2 Ghost 的默认 SEO 行为与局限性
Ghost 在设计之初就内置了诸多 SEO 最佳实践,如自动生成 Sitemap、Canonical 标签、Open Graph 协议支持等 1。然而,这些功能主要针对公开可见的元数据(Metadata),而非受保护的正文内容。
2.2.1 Sitemap 与索引发现
Ghost 会将所有发布的文章,无论其访问级别(Public, Members only, Paid members only),都包含在 sitemap.xml 中 2。这确保了 Googlebot 能够“知道”这些页面的存在并进行抓取。这是 SEO 的第一步:发现(Discovery)。
2.2.2 抓取与渲染的断层
当 Googlebot 顺着 Sitemap 抓取一个 Paid members only 的页面时,它获得的是一个内容极其稀薄的页面。根据 Google 的算法逻辑:
- 如果页面主要内容(Main Content, MC)过少,可能会被归类为“软 404”或“低质量页面”。
- 页面无法针对正文中的长尾关键词(如具体的技术名词、数据分析结果、独特的观点陈述)进行排名。
- 虽然页面可能被索引,但其在搜索结果中的摘要(Snippet)可能无法准确反映文章的核心价值,导致点击率(CTR)低下。
2.2.3 结构化数据的缺失
Ghost 默认通过 {{ghost_head}} 助手输出 Schema.org 结构化数据,通常是 Article 或 NewsArticle 类型。然而,原生的 Ghost 并没有根据 Google 的付费墙指南自动添加 isAccessibleForFree: false 以及相关的 hasPart 属性 3。这就造成了一个尴尬的局面:Ghost 给 Googlebot 看的是残缺的内容,同时又没有明确告诉 Googlebot “这是因为付费墙”,导致 Google 可能会误以为这就是一篇只有两段话的劣质文章。
2.3 公开预览(Public Previews)的策略意义
为了缓解上述问题,Ghost 引入了“公开预览”功能,允许作者在编辑器中手动插入一个分界线。分界线以上的内容对所有人可见,以下的内容被服务端截断 1。如图所示:
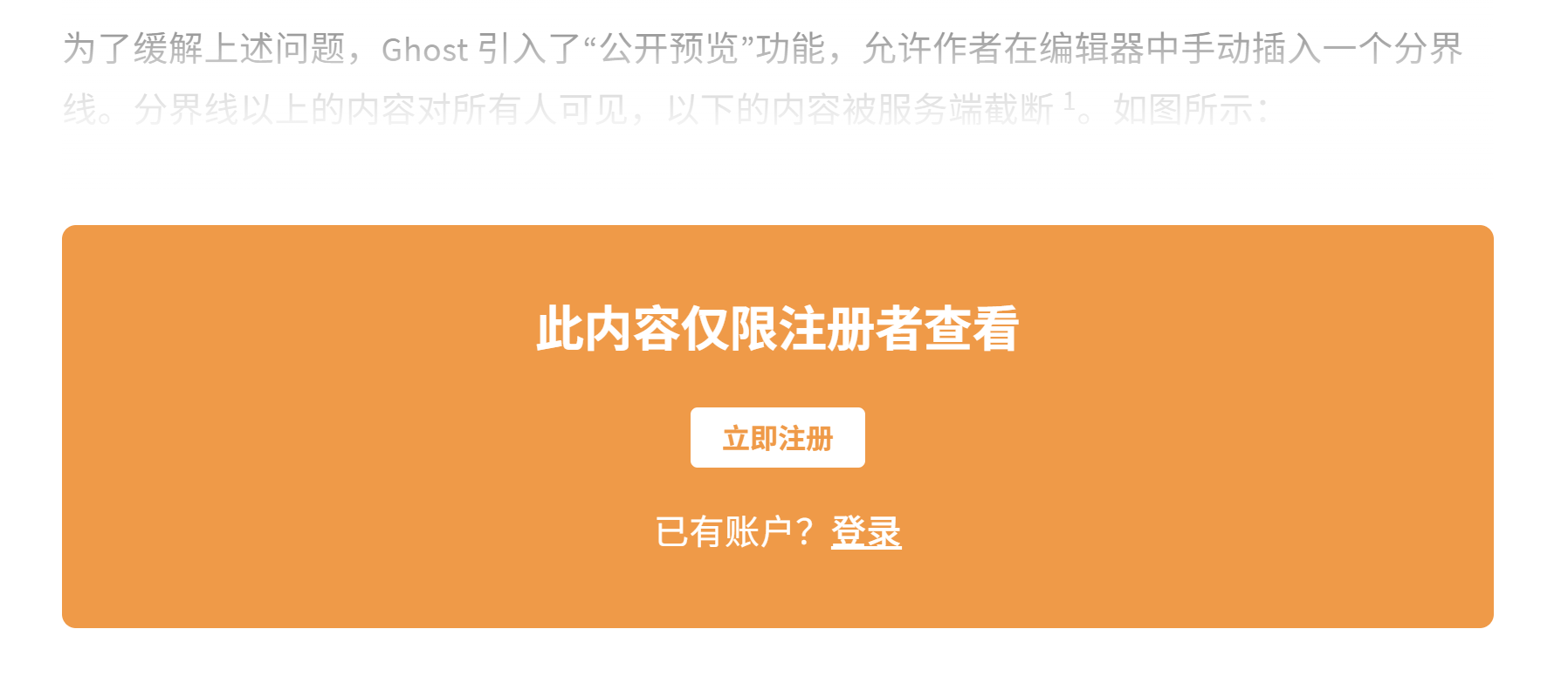
这是一种内容分段策略。从 SEO 角度看,我必须成为“摘要大师”。如果希望文章获得排名,必须在公开预览部分密集地部署关键词、概括核心论点,提供足够的价值以满足用户的初步搜索意图,同时又要留下足够的悬念促使转化。这在实际操作中对写作技巧要求极高,且全文并未被爬虫深度阅读和索引。
所以我的初始版本,虽然添加了公开预览,但因为注册墙以及内容过少,还是被判定为垃圾内容。最终通过更改文章地址(slug),重新提交 GSC 才被成功抓取,因为新的 url 对谷歌来说就是新的页面,不会被垃圾标签影响。
2.4 Ghost 核心机制总结

Ghost CMS 打从一开始,就选择走内容保护的路线。通过中间件进行身份验证,凡是未登录用户,服务器一开始渲染输出的内容就是残缺的摘要或者预览版本。用户客户端接收到的内容就是残缺的,好比书店出版了一本书,但是免费读者一进门,店员就只提供印刷了第一章节的书给用户。
其次,Ghost 的 SEO 机制,并没有遵循谷歌的付费内容指南,没有自动标识付费内容。好比谷歌的爬虫进了书店,店员同样提供一本只印刷了第一章的书,并且还不告诉谷歌:”这是付费内容,你没付费,所以只有第一章“。那谷歌的爬虫就会默认,你这第一章的书就是全部内容了,继而算法判断:一本书就写了一章,垃圾内容,不予收录。
3. 标杆对比:WSJ 与彭博社的付费墙技术架构
说完 Ghost 的处理逻辑,来看看出版界顶流是如何处理付费内容的 SEO 的。
3.1 动态服务与爬虫白名单
企业级媒体的核心 SEO 策略是动态服务,即根据请求者的身份提供不同版本的 HTML 文档。这与响应式设计不同,后者是同一套 HTML 适应不同屏幕尺寸,而前者是服务器端产生的不同 HTML。
简单理解就是,顶级出版社会在服务器端渲染不同版本的文章内容:摘要预览版、部分正文版、全文版,然后看人下菜,针对不同的访客,提供不同的版本。
例如当质检部门的人员上门(搜索引擎爬虫),店员会把完整印刷的书提供给他审阅,确保书店的内容能被登记在册、推荐给更多读者。当一位路人首次进店(新用户),店员可能会大方地让他翻阅完整版本,培养阅读兴趣。但当这位路人频繁来店却始终不买(高频回访未付费用户),店员就会逐渐收紧,最终只提供印刷了第一章的试读本,并附上一句:"后续内容请购买完整版。”
不难发现,这样做能利益最大化,但核心在于身份识别。出版社如果身份识别有误,错误的把本应给质检人员的完整版本给了路人,那书店就损失了这部分收益,甚至导致内容被盗版分发。同时,还要防止有路人假扮质检人员来骗取完整版本。所以像 Bloomberg 这样的媒体都会用以下的方式,自建一套严格的用户识别系统。
3.1.1 针对 Googlebot 的特殊通道
WSJ 和 Bloomberg 维护着极其严格的 Googlebot 识别机制。当服务器接收到请求时:
- User-Agent 嗅探:初步判断 UA 字符串是否包含 "Googlebot"。
- DNS 反向查找:为了防止伪造(Spoofing),服务器会对请求 IP 进行反向 DNS 查询,确认其确实属于 googlebot.com 或 google.com 域 5。
- 全量渲染:一旦确认为真 Googlebot,服务器会绕过付费墙逻辑,渲染并返回包含完整正文的 HTML。
这种机制确保了 Google 拥有该文章的“上帝视角”,能够索引每一个字符,从而在搜索排名中占据优势。
3.1.2 “伪装”(Cloaking)的合规化
向 Googlebot 展示全文而向用户展示付费墙,这在技术上符合“伪装”的定义,通常是被 Google 严厉惩罚的黑帽 SEO 技术。然而,WSJ 等媒体通过严格遵循 Google 的 "Subscription and Paywalled Content" 结构化数据指南,使其行为合法化 6。
他们会在页面中嵌入如下 JSON-LD 数据,明确告知 Google:
"这个页面包含付费内容。我给你看的是完整的,用户需要付费才能看到。这不是欺骗,这是商业模式。"
这一声明是企业级付费墙 SEO 的基石。Ghost 的原生功能中恰恰缺失了这一自动化的、精细的声明机制 8。
3.2 计量式与倾向性模型
与 Ghost 简单的“二元门控”(付费/不付费)不同,WSJ 采用了更为复杂的倾向性评分模型(Propensity Score) 10。
动态门槛:系统会根据用户的来源(如从 Google 搜索点击进入、从社交媒体进入、直接访问)、历史访问行为、设备类型等计算一个分数。
差异化体验:
- 对于“冷”用户(首次访问),可能展示全文,或者允许免费阅读,以培养阅读习惯。
- 对于“温”用户(多次回访),可能展示计量器(剩余 1 篇免费)。
- 对于“热”用户(高频访问且未订阅),则展示严格的付费墙。
技术实现:这通常依赖于客户端 JavaScript 结合服务端逻辑。内容往往已经加载到了用户的浏览器中,只是通过 CSS 模糊或遮罩层进行了隐藏(即“软”付费墙)。这种方式虽然安全性较低(容易被插件破解),但极大地提升了用户体验和 SEO 友好度,因为内容本身就在页面上 9。
3.3 差距分析总结
下表总结了 Ghost CMS 原生状态与企业级媒体架构在付费墙 SEO 上的关键差距:
表 3.1:Ghost 原生架构 vs. 企业级媒体架构对比
通过对比可见,Ghost 的设计哲学侧重于创作者资产保护与简易性,而牺牲了部分 SEO 灵活性。 WSJ 和 Bloomberg 等顶级媒体则侧重于流量最大化与漏斗转化,愿意为此承担更高的技术复杂度和适度的内容泄露风险。
4. 解决方案:在 Ghost 上实现付费内容 SEO
4.1 方案 A:主题修改的客户端软付费墙(最大化 SEO 但安全折衷)
这是复刻 WSJ “软”付费墙体验的最直接方式。其核心思想是:欺骗 Ghost 服务器,让其认为所有内容都是公开的,但在用户浏览器端通过 JavaScript 重新实施访问控制。
4.1.1 技术实现步骤
- Ghost 后台设置:将所有希望被 Google 索引的付费文章,其访问权限(Access Level)设置为 Public。这一步至关重要,它确保了 Ghost 服务器会渲染并输出包含全文的 HTML 13。
- 主题模板改造 (post.hbs):我们需要在 Handlebars 模板中注入逻辑,用于在客户端判断用户权限。由于 Handlebars 运行在服务端,我们需要将用户的登录状态“泄漏”给客户端 JavaScript。在 post.hbs 中,我们不直接输出 {{content}},或者将其包裹在一个特定的容器中:
<div class="gh-content gh-canvas" data-access="{{#if @member.paid}}paid{{else}}free{{/if}}">
{{content}}
</div>
{{!-- 注入客户端控制脚本 --}}
<script>
document.addEventListener('DOMContentLoaded', function() {
// 检查由 Ghost 设置的成员 Cookie,或者检查 data 属性
// 注意:依赖 data 属性可能不够,因为 Public 页面下 @member 可能为空
// 更可靠的是检查 'ghost-members-ssr' cookie
const hasMemberCookie = document.cookie.includes('ghost-members-ssr');
const contentDiv = document.querySelector('.gh-content');
if (!hasMemberCookie) {
// 用户未登录,实施软付费墙
contentDiv.classList.add('paywall-active');
// 插入遮罩层
const paywallOverlay = document.createElement('div');
paywallOverlay.className = 'paywall-overlay';
paywallOverlay.innerHTML = '<h2>Subscribe to read the full story</h2>...';
contentDiv.appendChild(paywallOverlay);
}
});
</script>- CSS 隐藏策略:为了防止内容闪烁(FOUC),可以使用 CSS 将内容默认模糊或限制高度。
4.1.2 方案 A 的 SEO 影响
- Googlebot 视角:由于 Googlebot 会抓取 HTML,它能看到完整的文章内容。虽然 Googlebot 现在的渲染能力很强,能执行 JavaScript,但通常它不会因为页面上有遮罩层就惩罚页面,只要结构化数据声明正确。
- 风险:这种方法实际上是将付费内容免费送达了每个用户的浏览器。任何稍有技术常识的用户都可以通过“检查元素”删除遮罩层,或者禁用 JavaScript 来阅读全文。这牺牲了安全性以换取 SEO 9。
其实之前华尔街日报(WSJ)没升级内容防护措施之前用的就是这种方案。那时候 Github 上的插件 Paywall Bypass 就是禁用 JavaScript 来绕过这个限制。因为全文已经加载到用户的设备端了,只是限制不展示给用户罢了。
但后来 WSJ 就升级了保护措施,同时发律师函给 Github,让 Github 下架这类插件,彻底断绝开发者分发插件的路径。所以说最强的版权保护还得靠法律啊。要不怎么说迪士尼拥有全球最强法务呢🤣
4.2 方案 B:基于 Cloudflare Workers 的边缘动态服务(企业级推荐方案)
这是最接近 Bloomberg 技术架构的方案,兼顾了安全性和 SEO,但技术实施难度最高。核心逻辑是在 Cloudflare 边缘节点(Edge)拦截请求,识别 Googlebot,并根据身份从 Ghost 后台获取不同版本的内容。
4.2.1 架构设计
流量路径:User/Bot -> Cloudflare Worker -> Ghost Origin
- 普通用户访问:Worker 识别为普通用户,直接透传请求给 Ghost。Ghost 执行原生的服务端权限检查,返回截断后的预览内容。安全性得到保障。
- Googlebot 访问:
- Worker 识别 User-Agent 为 Googlebot,并验证 IP。
- Worker 代替用户向 Ghost 发起一个特权请求。由于 Ghost Content API 仅返回公开数据,我们需要使用 Ghost Admin API 来获取完整 HTML 14。
- Worker 获取到完整 HTML 后,通过 HTMLRewriter 注入 JSON-LD 结构化数据(声明 Paywall)。
- Worker 将合成后的完整响应返回给 Googlebot。
4.2.2 Cloudflare Worker 代码逻辑实现
以下是一个简化的 Worker 逻辑代码,展示如何实现这一复杂的流程:
import GhostAdminAPI from '@tryghost/admin-api';
export default {
async fetch(request, env, ctx) {
const url = new URL(request.url);
const userAgent = request.headers.get('User-Agent') |
| '';
// 1. 严格的 Bot 识别 (简化版,生产环境需验证 IP)
const isGooglebot = /Googlebot|bingbot/i.test(userAgent);
// 如果不是 Bot,或者是静态资源,直接放行
if (!isGooglebot |
| url.pathname.match(/\.(css|js|png|jpg|woff)$/)) {
return fetch(request);
}
// 2. Bot 访问处理:尝试获取完整内容
try {
// 初始化 Ghost Admin API (需在 Env 中配置 Key)
// 注意:直接在 Worker 中使用 Admin API 需要处理 JWT 生成
// 这里假设有一个封装好的 fetchFullContent 函数
const fullPost = await fetchFullPostFromGhost(url.pathname, env);
if (fullPost) {
// 3. 注入 Schema 并返回
return new HTMLRewriter()
.on('head', new SchemaInjector(fullPost))
.transform(new Response(fullPost.html, {
headers: { 'Content-Type': 'text/html' }
}));
}
} catch (e) {
// 出错时回退到普通请求,保证服务可用性
console.error(e);
}
return fetch(request);
}
}
// 辅助类:注入 Paywall Schema
class SchemaInjector {
constructor(post) { this.post = post; }
element(element) {
const schema = {
"@context": "https://schema.org",
"@type": "NewsArticle",
"headline": this.post.title,
"isAccessibleForFree": false,
"hasPart": {
"@type": "WebPageElement",
"isAccessibleForFree": false,
"cssSelector": ".gh-content"
}
};
element.append(`<script type="application/ld+json">${JSON.stringify(schema)}</script>`, { html: true });
}
}4.2.3 关键技术挑战
- Admin API 限制:Ghost Admin API 是为管理设计的,速率限制(Rate Limiting)较严。如果 Googlebot 高频抓取,可能触发限制。解决方案是在 Worker 层利用 Cloudflare KV 或 Cache API 缓存从 Admin API 获取的完整内容 16。
- 缓存中毒(Cache Poisoning)风险:必须确保 Cloudflare 的 CDN 缓存不会将 Googlebot 看到的“全文版”错误地分发给后续访问的普通用户。这需要在 Worker 中显式控制 Cache Key,或者设置 Vary: User-Agent 响应头(虽然 Cloudflare 默认忽略 Vary,需要企业版或特定配置支持)。
4.3 方案 C:结构化数据注入(Schema Injection)
无论采用方案 A 还是 B,都需要正确的结构化数据。Ghost 原生的 {{ghost_head}} 无法输出 Paywall Schema,因此必须手动介入。
不然只提供付费内容给谷歌,但是不声明是因为付费墙(paywall)才特殊对待的,妥妥的 SEO 欺诈。因为你为了更好的排名,提交优质内容给谷歌的爬虫,但是真实用户看到的却是缺失的内容。这属于挂羊头卖狗肉,是谷歌严厉打击的 SEO 行为。
4.3.1 JSON-LD 规范详解
Google 要求在 <head> 中包含 NewsArticle 或 Article 对象,并具备以下属性:
- isAccessibleForFree: 布尔值,必须设为 False。
- hasPart: 一个对象,描述页面的哪个部分被锁住了。
- cssSelector: 字符串,必须对应页面上包含付费内容的容器的 CSS 类名(如 .gh-content 或 .c-content)。
表 4.1:Ghost 原生 Schema 与 Paywall Schema 对比
4.3.2 在 Ghost 中的注入方法
由于无法直接修改 {{ghost_head}} 的输出,我们采用“追加覆盖”法。
- 在 Ghost 后台 -> Code Injection -> Site Header。
- 插入自定义脚本,利用 Ghost 输出的变量(如果是 Public 页面)或硬编码逻辑。
- 更好的方式是在主题的 default.hbs 中,在 {{ghost_head}} 之后手动添加一段 Handlebars 代码:
{{#post}}
{{#unless access}}
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"mainEntityOfPage": "{{url absolute="true"}}",
"headline": "{{title}}",
"datePublished": "{{date published_at format="YYYY-MM-DDTHH:mm:ssZ"}}",
"dateModified": "{{date updated_at format="YYYY-MM-DDTHH:mm:ssZ"}}",
"isAccessibleForFree": false,
"hasPart": {
"@type": "WebPageElement",
"isAccessibleForFree": false,
"cssSelector": ".gh-content"
}
}
</script>
{{/unless}}
{{/post}}注意:这会导致页面上出现两个 Article Schema(一个是 Ghost 自动生成的,一个是手动的)。Google 通常能够处理这种情况,或者优先读取更详细的那一个,但这并非完美方案。最完美的方案是在 Cloudflare Worker 层(方案 B)利用 HTMLRewriter 剔除原生的 Schema 并注入新的。
5. 总结
表 5.1:三种 SEO 策略的综合评估矩阵
总之,我这种个人博客,费大力气做企业级的付费内容 SEO 并不值当。使用 Ghost 默认的 SEO 配置就已满足绝大部分需求了。以后若还有内容需要添加付费墙,那就使用公开预览,多开放一些正文到预览区呗。折腾一大圈,最后不也是把文章全部公开了吗。
这次经验,倒是对出版行业的付费内容如何做 SEO 有了全面的了解。其实付费内容的 SEO 核心在于如何平衡付费内容的私密性与搜索引擎排名的公开性之间的矛盾。目前来看,出版业选择相信谷歌,对于谷歌的爬虫免费公开全部内容。这背后可能是行业监管、现实利益等综合博弈后的结果。
参考链接:
- How to leverage SEO for a membership website
https://ghost.org/resources/seo-membership-websites/ - Is protected content indexed by search engines?
https://ghost.org/help/is-protected-content-indexed/ - Schema org generate - Bugs - Ghost Forum
https://forum.ghost.org/t/schema-org-generate/36772 - Paywall content - Marketing & promotion - Ghost Forum
https://forum.ghost.org/t/paywall-content/35247 - Forget IPs: using cryptography to verify bot and agent traffic - Cloudflare Blog,
https://blog.cloudflare.com/web-bot-auth/ - JavaScript Paywalls | Google's Updated Guidance - 6S Marketers
https://6smarketers.com/googles-updated-guidance-on-javascript-paywalls/ - Structured data for subscription and paywalled content ( CreativeWork ) - Google for Developers
https://developers.google.com/search/docs/appearance/structured-data/paywalled-content - Paywall structured data seo - Ideas - Ghost Forum
https://forum.ghost.org/t/paywall-structured-data-seo/35272 - Add structured data for paid content to be indexed in Google search - Ghost Forum
https://forum.ghost.org/t/add-structured-data-for-paid-content-to-be-indexed-in-google-search/36477 - Behind the Wall Street Journal paywall that decides when readers are ready to subscribe
https://www.thedrum.com/news/behind-the-wall-street-journal-paywall-decides-when-readers-are-ready-subscribe - After years of testing, The Wall Street Journal has built a paywall that bends to the individual reader - Nieman Lab
https://www.niemanlab.org/2018/02/after-years-of-testing-the-wall-street-journal-has-built-a-paywall-that-bends-to-the-individual-reader/ - I Created A Metered Paywall - Free Code - Memberships & subscriptions - Ghost Forum
https://forum.ghost.org/t/i-created-a-metered-paywall-free-code/50575 - What if I want to do paywalls 'wrong'? - Spectral Web Services
https://www.spectralwebservices.com/blog/what-if-i-want-to-do-paywalls-wrong/ - Fetch posts without Ghost Admin API from Cloudflare Worker
https://forum.ghost.org/t/fetch-posts-without-ghost-admin-api-from-cloudflare-worker/27756 - Scoped API Permissions - Integrations & API - Ghost Forum
https://forum.ghost.org/t/scoped-api-permissions/36892 - Request · Cloudflare Workers docs
https://developers.cloudflare.com/workers/runtime-apis/request/ - Increase the performance of your self-hosted ghost blog massively with proper caching in Cloudflare
https://forum.ghost.org/t/increase-the-performance-of-your-self-hosted-ghost-blog-massively-with-proper-caching-in-cloudflare/43419

